Machine learning systems learn from data, but how they learn depends on the structure of that data and the goals defined by humans. Two foundational approaches dominate this landscape: supervised learning and unsupervised learning. While both aim to uncover patterns and generate useful insights, they differ fundamentally in data requirements, learning mechanisms, and real-world applications. Understanding these approaches is essential for grasping how modern AI systems are built, evaluated, and deployed across industries.
What Is Supervised Learning?
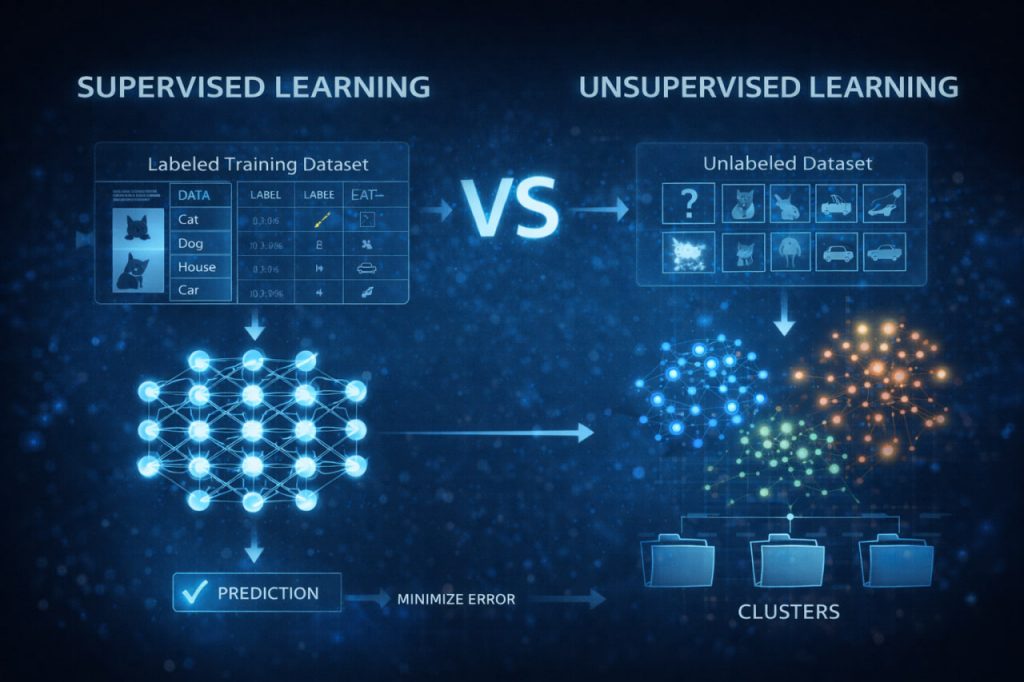
Supervised learning is a machine learning approach where models are trained on labeled data, meaning each input example is paired with a correct output. The algorithm’s task is to learn a mapping between inputs and known targets so it can make accurate predictions on new, unseen data. Common use cases include classification (such as spam detection) and regression (such as price prediction). The presence of labels provides clear guidance, allowing the model to measure its errors and improve iteratively.
“Supervised learning works because the system is constantly corrected against known outcomes, much like a student learning with an answer key,” — Dr. Michael Turner, applied machine learning scientist.
How Supervised Learning Models Learn
During training, a supervised model makes predictions and compares them to the correct labels using a loss function, which quantifies error. This error is minimized through optimization techniques such as gradient descent, gradually improving accuracy. Algorithms commonly used in supervised learning include linear regression, logistic regression, support vector machines, and neural networks. Because performance can be directly measured, supervised learning is well suited for tasks where precision and reliability are critical.
Strengths and Limitations of Supervised Learning
The main strength of supervised learning is its predictive accuracy, especially when high-quality labeled data is available. However, labeling data is often expensive, time-consuming, and prone to human bias. Supervised models can also struggle when faced with data distributions that differ significantly from their training set.
“Supervised learning systems are powerful but only as reliable as the data and labels we provide,” — Dr. Helen Brooks, AI governance expert.
What Is Unsupervised Learning?
Unsupervised learning operates without labeled outputs, meaning the model must discover structure in the data on its own. Instead of learning from predefined answers, the algorithm explores patterns, similarities, and relationships inherent in the dataset. Common tasks include clustering, dimensionality reduction, and anomaly detection. Unsupervised learning is particularly valuable when dealing with large, complex datasets where labeling is impractical or impossible.
“Unsupervised learning allows machines to explore data the way scientists do—by looking for structure before defining meaning,” — Dr. Sofia Mendes, data science researcher.
Core Techniques in Unsupervised Learning
Popular unsupervised algorithms include k-means clustering, hierarchical clustering, principal component analysis (PCA), and autoencoders. These methods group similar data points, compress information, or identify outliers without explicit instructions. For example, clustering can reveal customer segments in marketing data, while dimensionality reduction helps visualize high-dimensional datasets. The insights produced often guide further analysis rather than provide direct predictions.
Strengths and Limitations of Unsupervised Learning
Unsupervised learning excels at discovery, uncovering hidden patterns humans may not anticipate. However, evaluating its success is more subjective because there are no labels to compare against. Results often require human interpretation to determine relevance and usefulness.
“Unsupervised learning generates hypotheses rather than answers, which makes it powerful but less deterministic,” — Dr. Alan Reeves, AI systems researcher.
Key Differences Between the Two Approaches
The central distinction lies in the availability of labeled data and the learning objective. Supervised learning focuses on prediction accuracy and predefined outcomes, while unsupervised learning emphasizes exploration and structure discovery. Supervised models answer questions like “What will happen next?” whereas unsupervised models ask “What patterns exist here?” In practice, many advanced systems combine both approaches to maximize insight and performance.
Real-World Applications and Hybrid Approaches
In real-world systems, supervised and unsupervised learning often work together. For example, unsupervised clustering may first identify user segments, which are then fed into supervised models for targeted predictions. This hybrid strategy reduces labeling costs while improving model robustness. Industries such as finance, healthcare, and transportation rely heavily on these combined workflows to balance efficiency and accuracy.
Conclusion
Supervised and unsupervised learning represent two complementary strategies for teaching machines from data. Supervised learning delivers precision through labeled guidance, while unsupervised learning unlocks discovery by revealing hidden structure. Understanding their differences clarifies how AI systems learn, adapt, and create value—and why choosing the right approach depends on both data availability and problem goals.


AI Race currently is an arms race between the countries. One the one hand, we have US with OpenAI, under tons of restrictions and being supervised by the US Laws, on the other hand we have China, unsupervised, attacking and scraping all the data it can have without any limitation from the internet. Even tho, China has joined this race late, they are making immense progress. US, has been actively building hundreds of billions worth of Data Centers around US, and now currently, after NVIDIA spent 1.5 Billion dollars to build a data center in Israel, around the world. Spesifically, US Allies. However, Data Centers, require a lot of Water, Electricity and pours out immense amount of damage to the enviroment. US Citizens are very much against the idea of getting a Data Center in their states. However, as you may now, due to the DOGE and American Senate has been sterilized by Elon, they do not have much say in it. So only side which were supervised is also going unhinged. China, well, who knows what China awful things they are doing to get one step ahead. They have already created AI Survalliance system, a technocracy, with digital ID and digital Currecy, and due to having sheer numbers on manpower, they have also immense data pouring from survailing their own people’s day to day life, which US can only dream of.
That being said, one thing I can surely tell you, this whole AI bubble, will get dirtier and dirtier in the upcoming years.